最近仕事でAndroidアプリの手伝いをしているが、 カスタムInputFilterの実装でやらかしてしまった。 基本的にはAPIの調査不足が原因である。 リリース前にわかって修正したので大事には至らなかったが、こういう防げるミスはしないようにしたい。
おそらくいっぱしのアンドロイダーであれば非常に基本的な内容なのだが、 いい機会なのでInputFilterに関して調べた内容をまとめておきたい。
まず、 API document から精読する。こういう基本的なことが非常に大事である。 今回はこの作業を怠ってしまったことが不幸の始まりである。
以下、InputFilterのfilterメソッドの説明
public abstract CharSequence filter (CharSequence source, int start, int end, Spanned dest, int dstart, int dend)
Added in API level 1
This method is called when the buffer is going to replace the range dstart … dend of dest with the new text from the range start … end of source. Return the CharSequence that you would like to have placed there instead, including an empty string if appropriate, or null to accept the original replacement. Be careful to not to reject 0-length replacements, as this is what happens when you delete text. Also beware that you should not attempt to make any changes to dest from this method; you may only examine it for context. Note: If source is an instance of Spanned or Spannable, the span objects in the source should be copied into the filtered result (i.e. the non-null return value). copySpansFrom(Spanned, int, int, Class, Spannable, int) can be used for convenience.
ざっくりと訳してみる。
このメソッドはbufferをdestのdstart からdendの範囲を sourceのstart から endの範囲の新しいテキストで置き換える際に呼ばれるメソッドである。 戻り値は代わりに代入したいを返すようにする。 場合によっては空文字列を返しても良い、元々の文字列を使用したい場合はnullを返せば良い。 長さ0の置換は、文字を削除するときに発生するので、取り消さないように注意されたい。 またこのメソッドでdestを変更しないように注意されたし。 特定の条件下でしか検証しないかもしれないが、以下を注意されたし: sourceがSpannedもしくはSpannableの場合、source内のspan objectsは フィルター後の結果(つまり nullでない戻り値)の中にはコピーされておくべきである。 copySpansFrom(Spanned, int, int, Class, Spannable, int)が便利に使えるであろう。
まとめるとこんな感じ
- 本来、入力中の文字がsourceのstartからendまでの文字で、destのdstartからdendと置換するよ
- 戻り値を変えればその値に置換するよ
- nullを返せば元の挙動のまま(つまりsourceのstart からendまでが挿入される)だよ
- sourceはSpannedもしくはSpannableの場合がありその場合は copySpansFrom(Spanned, int, int, Class, Spannable, int)を使って値をコピーして使ってね
Spanned, Spannable というのが出てきた。こちらも API documentを見てみる。
Spanned のinterfaceの説明:
This is the interface for text that has markup objects attached to ranges of it. Not all text classes have mutable markup or text; see Spannable for mutable markup and Editable for mutable text.
訳:
これはある範囲にマークアップオブジェクトをもつテキストのためのインタフェースである。 すべてのテキストクラスがmutalbleなマークアップもしくはテキストをもっているわけではない。 mutableなマークアップについてはSpannable をmutableなテキストについてはEditableを参照されたし。
テキストの一部がボールドになっているとかそういうやつのためのものだろう。
Spannableのinterfaceの説明:
This is the interface for text to which markup objects can be attached and detached. Not all Spannable classes have mutable text; see Editable for that.
訳:
これはつけたり、外したりが可能なマークアップをもつテキストのためのインタフェースである。
なるほど、変換中というのがマークアップとして表されているのかなとなんとなく想像できる。
おおよそ理解はできた。 実際に動かしてみて動作を確認してみよう。 filterメソッドの引数の内容をログに出力してみる。
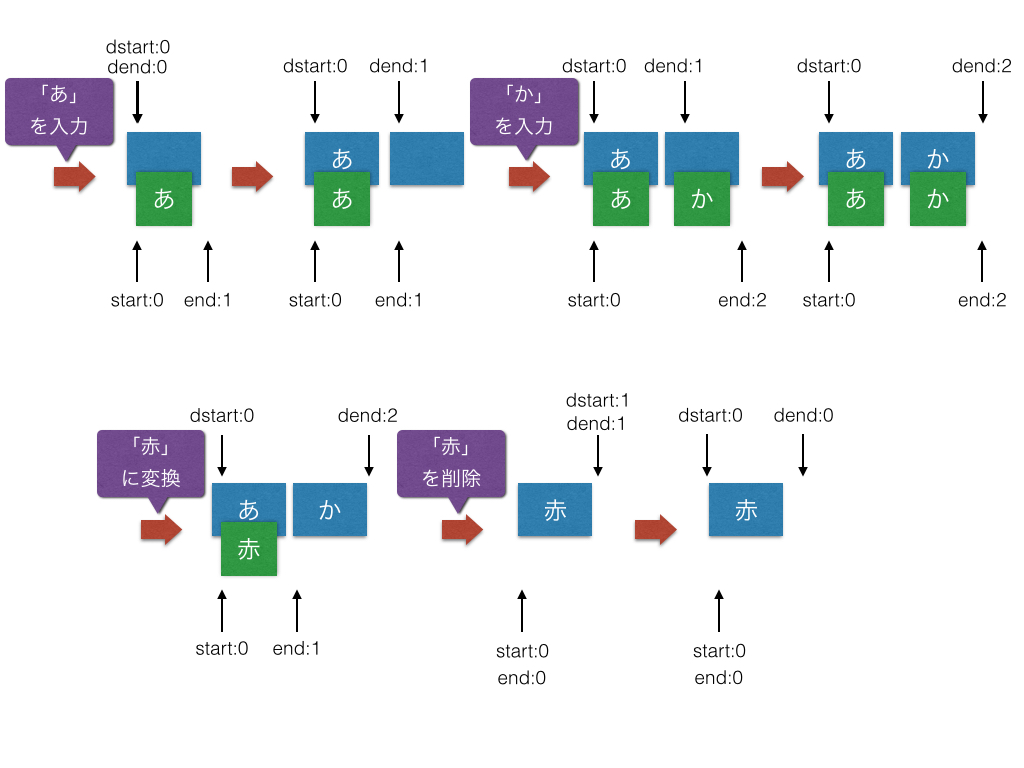
「あか」と順番に入力したとき
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: あ, start: 0, end: 1, dest , dstart: 0, dend: 0
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: あ, start: 0, end: 1, dest あ, dstart: 0, dend: 1
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: あか, start: 0, end: 2, dest あ, dstart: 0, dend: 1
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: あか, start: 0, end: 2, dest あか, dstart: 0, dend: 2
図にするとこんな感じである。
これは基本的なケースである。 もう少しいろいろなケースを試してみる。 「あか」と入力して、候補の「赤」を選択して、それを削除してみる。
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: あ, start: 0, end: 1, dest , dstart: 0, dend: 0
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: あ, start: 0, end: 1, dest あ, dstart: 0, dend: 1
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: あか, start: 0, end: 2, dest あ, dstart: 0, dend: 1
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: あか, start: 0, end: 2, dest あか, dstart: 0, dend: 2
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: 赤, start: 0, end: 1, dest あか, dstart: 0, dend: 2
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: , start: 0, end: 0, dest 赤, dstart: 1, dend: 1
I/io.kumabook.japanese_filter.JapaneseFilter(25584): source: , start: 0, end: 0, dest 赤, dstart: 0, dend: 1
また、TextUtils.dumpSpans でsource, destの中のマークアップの詳細をみることができる。 source内で、未確定の文字列にandroid.text.style.UnderlineSpan, android.view.inputmethod.ComposingTextとして表現されているのがわかる。
図示すると、このようになる。
おおよそInputFilterの動きがわかったところで、入力をひらがなと漢字だけに制限するフィルターを書いてみよう。 ひらがなと漢字だったらそのまま、カタカナだったらひらがなに変換し、それ以外だったら削除する。
public class JapaneseFilter implements InputFilter {
private final static String TAG = JapaneseFilter.class.getName();
@Override
public CharSequence filter(CharSequence source, int start, int end, Spanned dest, int dstart, int dend) {
Log.i(TAG, String.format("source: %s, start: %s, end: %s, dest %s, dstart: %s, dend: %s", source, start, end, dest, dstart, dend));
StringBuilder sBuilder = new StringBuilder();
TextUtils.dumpSpans(source, new StringBuilderPrinter(sBuilder), "JapaneseFilter:source");
Log.i(TAG, sBuilder.toString());
StringBuilder dBuilder = new StringBuilder();
TextUtils.dumpSpans(dest, new StringBuilderPrinter(dBuilder), "JapaneseFilter:dest");
Log.i(TAG, dBuilder.toString());
StringBuilder builder = new StringBuilder();
String src = source.subSequence(start, end).toString();
int ignoredCount = 0;
for (int i = 0; i < src.length(); i++) {
int codePoint = src.codePointAt(i);
if (isHiragana(codePoint) || isKanji(codePoint)) {
builder.append(src.charAt(i));
} else if (isKatakana(codePoint)) {
builder.append(katakana2hiragana(src.charAt(i)));
} else {
ignoredCount++;
}
}
if (source instanceof Spanned) {
SpannableString sp = new SpannableString(builder);
TextUtils.copySpansFrom((Spanned) source, start, end - ignoredCount, null, sp, start);
return sp;
} else {
return builder;
}
}
static private boolean isHiragana(int codePoint) {
return 0x3040 <= codePoint && codePoint <= 0x309F;
}
static private boolean isKatakana(int codePoint) {
return 0x30A0 <= codePoint && codePoint <= 0x30ff;
}
static private boolean isKanji(int codePoint) {
return (0x4E00 <= codePoint && codePoint <= 0x9FCC) ||
// 02_CJK Unified Ideographs Extension A [3400–4DB5].pdf
(0x3400 <= codePoint && codePoint <= 0x4DB5) ||
// 03_CJK Unified Ideographs Extension B [20000–2A6D6].pdf
(0x20000 <= codePoint && codePoint <= 0x2A6D6) ||
// 04_CJK Unified Ideographs Extension C [2A700–2B734].pdf
(0x2A700 <= codePoint && codePoint <= 0x2B734);
}
static private char katakana2hiragana(char c) {
return (char) (c - 'ァ' + 'ぁ');
}
}
ポイントはsourceがSpannedのときその状態をTextUtils.copySpansFromで戻り値にも反映する部分。 削除した数を覚えておかないとIndexOutOfBoundsExceptionになってしまうので注意。 また、ローマ字入力時のように一度禁止したい文字列を入力してから、その後変換確定して最終的な文字列を入力する場合にも、 TextUtils.copySpansFromで変換状態を維持していれば、表示上は禁止した文字列は表示されないがIMEの内部には残っているようなので大丈夫。
実はAndroid開発は3年くらいちゃんとはやっていない。 地道にアンドイダーとしての熟練度をあげなければ。 かけだしアンドロイダー→したっぱアンドロイダーぐらいにランクアップしたかな。 めざせキングアンドロイダー。